Python3中使用的socks5代理账号密码不能包含#*等字符原因是什么, 怎么解决
大白话系列之:python3的requests库socks5代理账号密码为什么不支持#等字符
前段时间遇到一个朋友说:测试个socks5账号居然出现神奇的现象, 参数设置进去以后抛出异常网络不可达。再跟进去一点, 发现参数居然只返回的部分, 甚至服务器地址都没有返回。后面各种测试发现只要账号密码包含#号, 就会出现这个问题。这个没理由的, socks5协议中没有要求账号密码不能包含#号, 一定是python3的库有问题。
每一次异常都不要轻易放过, E蜘蛛瀏覽器(EspiderBrowser)开发中经常遇到, 尽力找到“为什么”。
测试代码如下:
1import requests 2 3proxy_data = { 4 "server": 'x.x.x.x', 5 "port": "456", 6 "user": "test", 7 "pwd": "test#123", 8} 9proxy = f'{proxy_data.get("user")}:{proxy_data.get("pwd")}@{proxy_data.get("server")}:{proxy_data.get("port")}' 10proxies = { 11 'http': 'socks5h://' + proxy, 12 'https': 'socks5h://' + proxy, 13} 14 15try: 16 requests.packages.urllib3.disable_warnings(InsecureRequestWarning) 17 url = "https://www.espiderbrowser.com" 18 response = requests.get(url, proxies=proxies, timeout=5, verify=False) #GBK 19 content = response.content.decode('utf-8') 20 print("content:",content) 21 response.close() 22except Exception as e: 23 print('Error', proxy, e) 24
1、问题出现了只能跟进去使用的requests库。E蜘蛛瀏覽器(EspiderBrowser)开发过程中也大量使用python3完成很多功能。
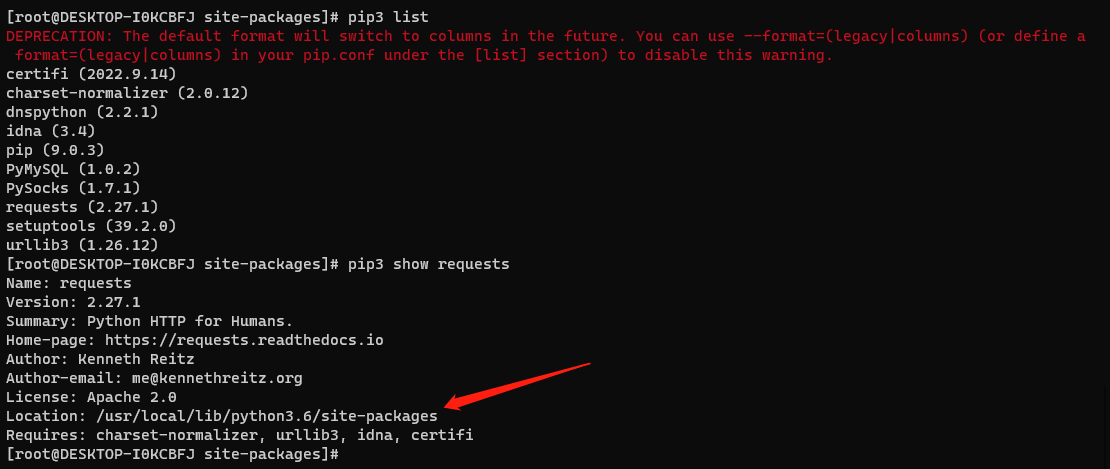
Ubuntu下这个库地址位于目录:/usr/local/lib/python3.6/site-packages
运行命令:pip3 list
再运行命令:pip3 show requests
确定好库的文件路径
2、打开requests库目录, api.py中就有get接口的申明
1def get(url, params=None, **kwargs): 2 r"""Sends a GET request. 3 4 :param url: URL for the new :class:`Request` object. 5 :param params: (optional) Dictionary, list of tuples or bytes to send 6 in the query string for the :class:`Request`. 7 :param \*\*kwargs: Optional arguments that ``request`` takes. 8 :return: :class:`Response <Response>` object 9 :rtype: requests.Response 10 """ 11 12 return request('get', url, params=params, **kwargs) 13
3、继续跟models.py:
1from urllib3.util import parse_url 2 3try: 4 scheme, auth, host, port, path, query, fragment = parse_url(url) 5except LocationParseError as e: 6 raise InvalidURL(*e.args) 7
4、继续跟urllib3/util/url.py;requests依赖了urllib3
1def parse_url(url): 2 """ 3 Given a url, return a parsed :class:`.Url` namedtuple. Best-effort is 4 performed to parse incomplete urls. Fields not provided will be None. 5 This parser is RFC 3986 and RFC 6874 compliant. 6 7 The parser logic and helper functions are based heavily on 8 work done in the ``rfc3986`` module. 9 10 :param str url: URL to parse into a :class:`.Url` namedtuple. 11 12 Partly backwards-compatible with :mod:`urlparse`. 13 14 Example:: 15 16 >>> parse_url('http://google.com/mail/') 17 Url(scheme='http', host='google.com', port=None, path='/mail/', ...) 18 >>> parse_url('google.com:80') 19 Url(scheme=None, host='google.com', port=80, path=None, ...) 20 >>> parse_url('/foo?bar') 21 Url(scheme=None, host=None, port=None, path='/foo', query='bar', ...) 22 """ 23 24 source_url = url 25 if not SCHEME_RE.search(url): 26 url = "//" + url 27 28 try: 29 scheme, authority, path, query, fragment = URI_RE.match(url).groups() 30 normalize_uri = scheme is None or scheme.lower() in NORMALIZABLE_SCHEMES 31
到这里问题就清晰了, socks5的账号密码是合成在url中传入的, 解析也用的是标准的url解析方式;This parser is RFC 3986 and RFC 6874 compliant。
那一定要用怎么解决呢?只能在传入的时候替换, 在解析完成以后替换回来, 具体替换代码如下:
1、修改urllib3/util/url.py, 把可能的#替换成’-’
1def parse_url(xurl): 2 url = str(xurl).replace("#","_-_") 3 if not url: 4 return Url() 5
2、修改urllib3/contrib/socks.py, 把”-“替换回来
1def __init__( 2 self, 3 proxy_url, 4 username=None, 5 password=None, 6 num_pools=10, 7 headers=None, 8 **connection_pool_kw 9 ): 10 parsed = parse_url(proxy_url) 11 12 if username is None and password is None and parsed.auth is not None: 13 split = parsed.auth.split(":") 14 if len(split) == 2: 15 username, password = split 16 if parsed.scheme == "socks5": 17 socks_version = socks.PROXY_TYPE_SOCKS5 18 rdns = False 19 elif parsed.scheme == "socks5h": 20 socks_version = socks.PROXY_TYPE_SOCKS5 21 rdns = True 22 elif parsed.scheme == "socks4": 23 socks_version = socks.PROXY_TYPE_SOCKS4 24 rdns = False 25 elif parsed.scheme == "socks4a": 26 socks_version = socks.PROXY_TYPE_SOCKS4 27 rdns = True 28 else: 29 raise ValueError("Unable to determine SOCKS version from %s" % proxy_url) 30 31 self.proxy_url = proxy_url 32 33 if password is not None: 34 password = str(password ).replace('_-_','#') 35
替换这两个修改后的py文件, 测试就可以正常跑通了。
这只是一次刨根问底而已, 正常情况下应该要遵守它默认的格式和协议。E蜘蛛瀏覽器(EspiderBrowser)等待用户来一次刨根问底。