React开发的网站网页如何获取原始数据
十年前的前端, 只要看到漂亮的很快完整克隆下来, 即使js混乱或者编码了, 都可以依靠工具还原绝大部分代码和功能, 还能修改自己想要修改的任意模块并使用;但是React流行以后, 这个不行了, 所有的代码都是webpack重新打包过的, 一些原始数据都不好拿了, 更有甚者还有自定义的混淆模块, nodejs上通用的混淆模块就够吃一壶了, 看到炫酷的功能直接复制不行了, 只能去各大论坛上找类似的实现, 暴力快捷不存在了, React把前端这个美丽免费蛋糕用箱子锁起来了。
E蜘蛛瀏覽器(EspiderBrowser)的资源中心:https://espiderbrowser.com/resource/ 网赚电商冲浪导航做的很完善, 很多用户看到这个导航有醍醐灌顶的冲击感, 那怎么把它的原始数据复制下来为自己网站所用呢?
根据这个需求想到的解决方案:
1、依靠chrome的另存为功能:【结果:失败!】
下载的html和js如下, 再全文搜索, 还是拿不到链接。
2、用爬虫工具, 实际模拟用户行为并记录, 获取数据:【结果:延后!】
用E蜘蛛瀏覽器(EspiderBrowser)的自动化脚本功能, 模拟访问并记录新打开的tab url的链接。这个理论上是可行的, 实际写起来还是需要花费不少时间。先押后优先级, 最为终极武器使用。
3、用React相关的开发辅助工具:【结果:成功!】
用react dev tools这个工具打开看看, 惊喜出现了
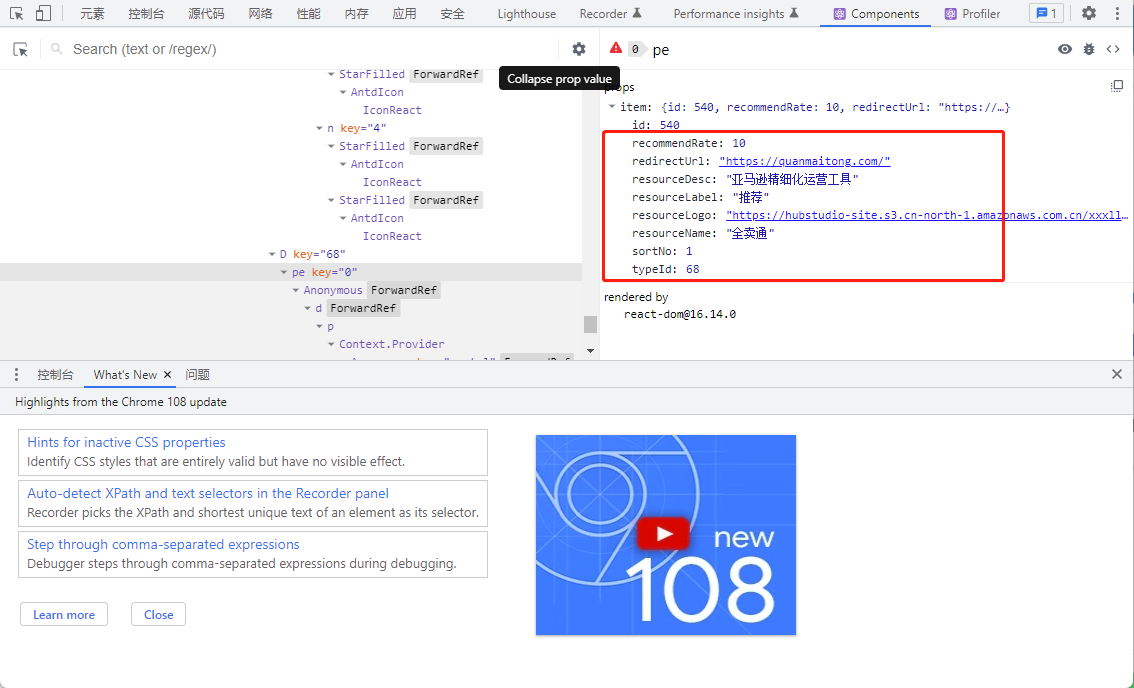
安装方法:在chrome中打开https://chrome.google.com/webstore/detail/fmkadmapgofadopljbjfkapdkoienihi 安装就行了。
注意:安装扩展以后, 需要重新刷新目标页让扩展正常跑起来才能完成后续操作。